传统的Image Animation工作主要是对一种类别的图像进行建模重建,比如单独针对人脸。但是在有些领域,比如对商品进行image animation,很难找到相关类型的数据或者模型。
后来有一种思路是直接用GAN进行训练,但是这需要对于每一个对象进行单独训练,比如训练一个人体运动就需要一段几十分钟甚至几小时的这个人运动的视频,然后单独对他进行训练,可以看出这种工作的泛用性是很差的。
METHOD
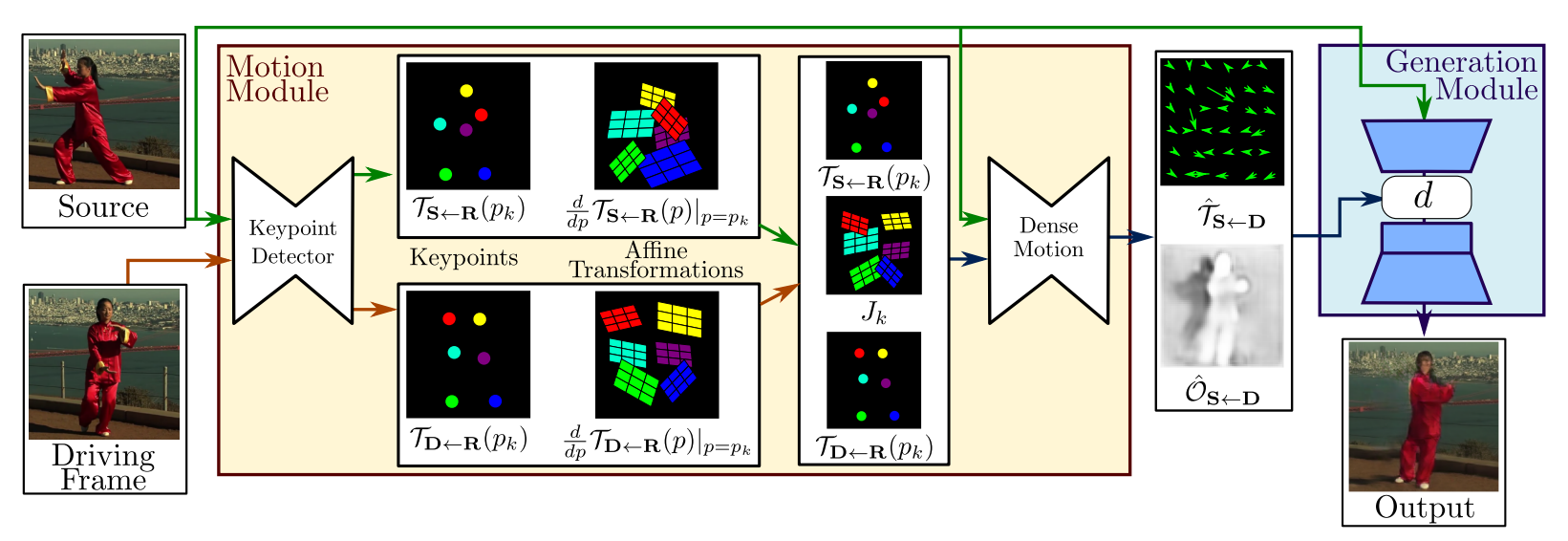
算法框架由两个模块组成:运动估计模块和图像生成模块。
MOTION MODULE
首先预测出一个由 3∗H∗W 的帧D到S的运动场 TS←D ,也被称为反向光流,这个场把D中每个像素的位置映射到S上。这里之所以用反向光流而不用正向光流,是因为反向光流在实现的时候可以通过双线性采样比较方便地算出。
由于T和D的来源未知,所以其差异可能会非常大,故直接进行 TS←D 的运算可能会导致计算误差比较大,于是作者在这里引入了一个中间量R,这个R实际上就是个抽象的中间量,后面会化简掉,没有实际的存在。
由此我们现在要预测的量变为了 TS←R 和 TR←D ,同时 TR←D=TD←R−1 ,所以可以把问题归结为 TX←R,X=(S,D) 。用 pk 表示R中的kp, zk 表示X中的kp,p、z分别表示R和X中的每一个像素,根据一阶泰勒展开可以得到:
TX←R(p)=TX←R(pk)+(dpdTX←R(p)∣p=pk)(p−pk)+o(∥p−pk∥)
根据雅可比矩阵表示可以得到:
TX←R(p)⋍{{TX←R(p1),dpdTX←R(p)∣p=p1},...,{TX←R(pk),dpdTX←R(p)∣p=pk}}
所以最终得出:
TS←D(z)=TS←R∘TD←R−1≈TS←R(pk)+Jk(z−TD←R(pk))Jk≈(dpdTS←R(p)∣p=pk)(dpdTD←R(p)∣p=pk)−1
在这个式子中, TS←R(pk) 和 TD←R(pk) 直接由关键点的预测模块得出。根据这个式子,我们可以通过每一个kp计算出一张变换后的图像 SK ,然后添加一张 S0=S 作为背景等静态部分。
与此同时,作者还额外计算出了k张heatmap来说明哪些部分出现了运动:
Hk(z)=exp(σ(TD←R(pk)−z)2)−exp(σ(TS←R(pk)−z)2)
然后把这些 Hk 和 SK 一起丢进网络,预测出 k+1张mask Mk ,这样一来,完整的运动场 T^S←D(z) 可以表示为:
T^S←D(z)=M0z+k=1∑KMk(TS←R(pk)+Jk(z−TD←R(pk)))
同时,网络还给出了一个mask O^S←D ,这个mask定义了哪些部分是由源图像扭曲可以得到,哪些部分是需要进行image inpainting预测出来。
GENERATION MODULE
图像生成模块实际上就是个用 S1 和 D1,...,DT 来生成 S2,...,ST 的过程,作者这里不是把 TS1←Dt(pk) 施加到 S1 上(我感觉这里应该是防止动作差异较大),而是把 TDt←D1(p) 施加到 S1 上:
TS1←St(z)≈TS1←R(pk)+Jk(z−TS←R(pk)+TD1←R(pk)−TDt←R(pk))
当然这样计算也存在一定的局限性,如果 S1 和 D1 的pose差异较大,计算出来的效果就不好。