如今已经有不少Motion Imitation的工作,这一工作旨在输入给程序一张静态人体图片与一个人体运动视频,来生成图片中的人模仿视频中动作的视频。
这篇paper做的也是这样的工作,此外,作者提出的网络还可扩展到Novel View Synthesis与Appearance Transfer的工作上。
Related Work
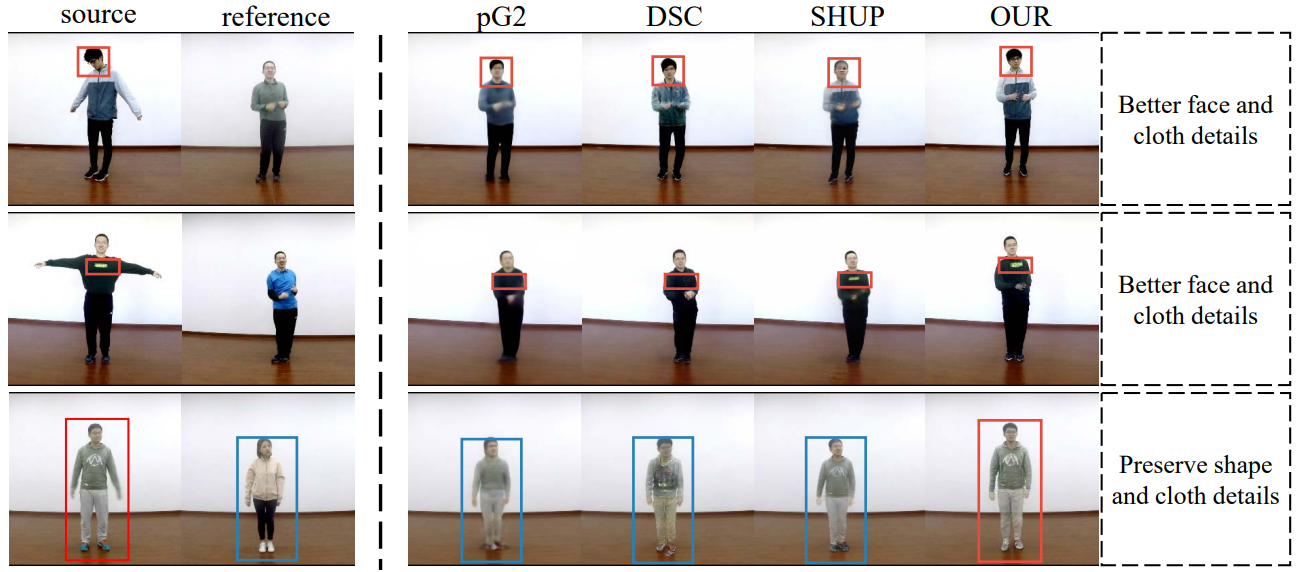
相关的工作已经有很多,但是他们往往是基于2D人体关键点的扭曲,这样的方案往往使得人体的形状信息(如高矮胖瘦)丢失,会把源图像的人体“压扁”或“拉伸”以扭曲成参考图像中人体的形状。
此外,由于许多工作是直接对整个人体进行建模,这样会导致如人脸、衣服纹理等细节信息被遗漏,而不能正确地生成。
Method
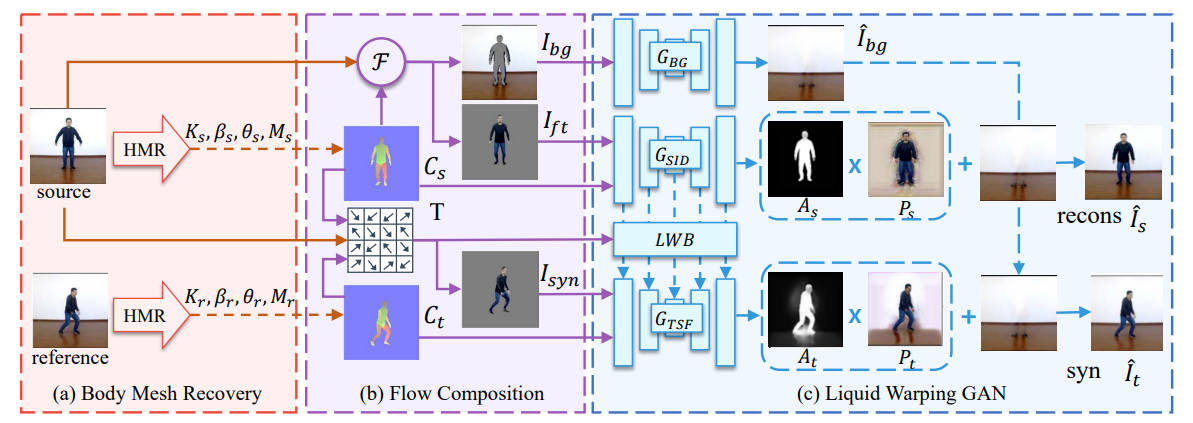
这篇文章基于之前工作的缺漏,提出了一个基于3D人体模型的网络。这个网络主要分为三个模块:人体网格重建模块、流合成模块以及最核心的Liquid Warping GAN模块。
人体网格重建
这个模块的输出即为整个网络的输出,是一张源图像与参考帧图像,参考帧图像取于参考视频独立的每一帧。这里首先使用了第三方的Human Mesh Recovery网络,来通过图像预测一个三维人体模型,该模型的存储结构为SMPL。
在SMPL模型中存储了 四个主要信息: 是一个弱透视相机,代表了将三维网格渲染回图像所需的相机, 由24个关节的三维旋转参数组成,而 则是存储了人体的shape信息, 则为三角面mesh。
流合成
这部分首先用上一步的相机与mesh通过第三方的Neural Mesh Renderer网络渲染出源图像与参考图像的二维对应图 ,这两张对应图只是对人体的粗糙表示,不包括头发、衣物等细节信息。
然后根据 与源图像 ,我们可以将 二值化,作为一个粗略的mask,将图像的前景 与背景 分别提取。
同时,根据两个三维模型中三角面的对应关系,我们可以计算出每个三角面中心的运动方向,并以 投影回平面,计算出 到 的运动场 ,即为 中每个像素点需要进行怎样的扭曲才能得到 。
将 与 做一个双线性采样,可以获得根据运动场扭曲的源图像 ,然后用 二值化后的mask与其进行遮罩,可以获得一个扭曲后的前景人物 。需要格外注意的是:尽管在pipeline的示意图中, 看似是一个很精确的前景人物,但必须指出:pipeline中的工作取的源图像与参考图像皆来自于同一视频,所以其人物的shape是相同的。在实际推断的过程中,并不能保证两者 的shape完全相同,所以以 计算的mask并不一定能和 很好地对应,所以会多取到一些背景部分、或者少取一部分前景,这都是正常的。
Liquid Warping GAN
这个模块由三个子网络组成:
- 对缺失的前景的背景图像 进行图像补全,生成完整的背景图像 。
- 是一个去噪卷积自编码器,其旨在提取出源图像中的人脸、衣服、纹理等identity信息。这个网络的输出为一张attention map 和一张color map 。将其与补全的背景图像结合: 计算出一张重建的源图像 ,并与原图计算感知loss,来不断优化这个自编码器。该编码器的结构类似于UNet与ResNet的结合,但两者并不共享参数。
- 的结构与 类似,只不过多了来自 的identity输入,该输入流通过Liquid Warping Block对齐后进行输入。
Liquid Warping Block
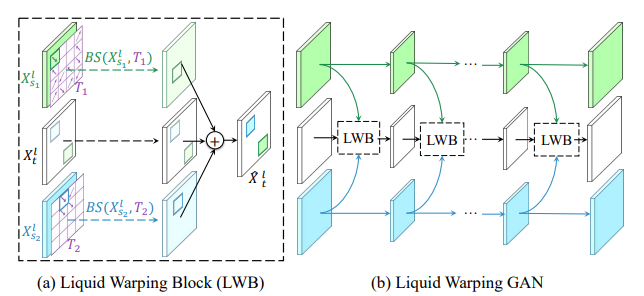
LWB的结构如图所示, 即为自编码器中第l层的feature map。首先将来自于 的 与之前预测出的运动场T进行双线性采样(图中绿色部分),然后将其与 对应层的feature map直接相加,得到结合后的feature map,作为下一层 的输入。
作者提出,由于有了LWB的结构,可以使多个源的feature map融合在一起,只需提供其对应的运动场T,即可实现多源的叠加,比如取出图1的人脸与图2的衣服以及图3的动作进行组合。
以上就是Generator的大体结构,Discriminator的部分参考了Pix2Pix这个工作的架构。
Loss
Loss主要分为四个部分:感知loss、人脸loss、GAN-loss与attention-loss,感知loss与人脸loss无非就是对生成结果与ground truth之间的L1 loss,没有什么特殊的部分,这里着重介绍一下attention-loss。
作者指出,预测出的attention map很容易饱和到全为1的情况,使用这样的饱和attention map与color map结合,就相当于把整张color map当作最终图像,并且完全覆盖掉背景。但是网络的输出其实只包括了人物前景,对于背景的预测完全是随机而错误的,需要弃用。
作者考虑到,既然attention map的作用是取出较为精确的前景,那就可以把渲染图 二值化后的mask 作为其的一个收敛目标,使生成的attention map更加接近 。但是前文也提到过, 是一个很粗糙的图像,不能完全作为标准,于是作者这里引入了一个总变差项 Total Variation Regularization:
这一项使得生成的attention map不会完全趋近于 ,而是在边缘部分更加平滑,这样的处理也可以使得前景与背景的轮廓过渡得更加自然。
完整的attention-loss计算如下:
Inference
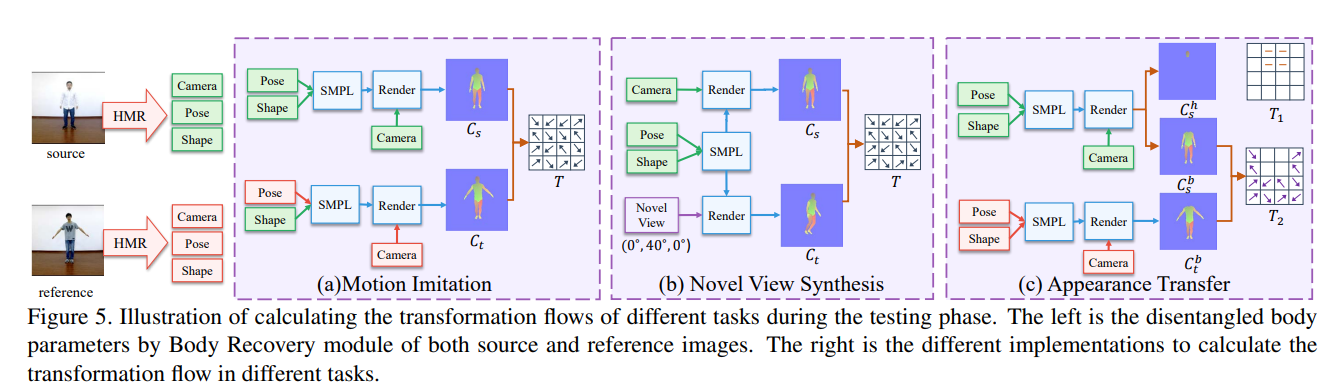
这篇文章的一大亮点就是提出了一个针对三个工作的统一网络。
在Novel View Synthesis工作上,由于我们已经有了由源图像建模出的3D模型,通过另一角度渲染出对应平面图并不是什么难题,有了渲染图,接下来的流程都与原模型相同。
而Appearance Transfer可以直接看作一个多源输入的问题,输入不同的mask与T,进行特征的融合生成即可。